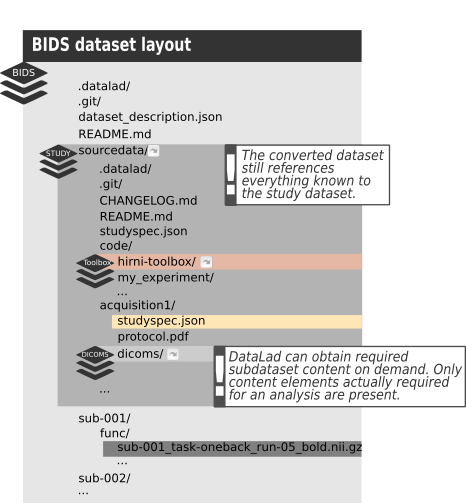
Basic workflow¶
Datalad-hirni comes with a set of commands aiming to support the following workflow to curate a study dataset and to convert it. This workflow to a degree reflects the envisioned structure of a study dataset as described in the concepts section.
This is a somewhat abstract description of what it is supposed to do. It might be more convenient for you to first see what you have to do by looking at the examples, showing this exact workflow: The creation of a study dataset here and afterwards the conversion.
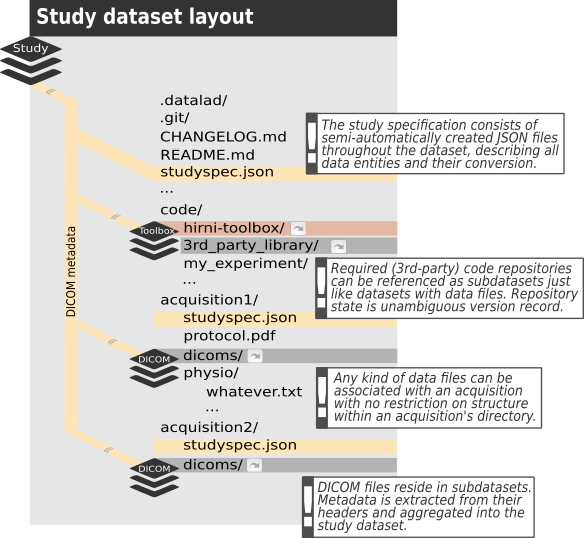
Build your study dataset¶
In order to build such a dataset that binds all your raw data, the first thing to do is to create a new dataset. To set
it up as a hirni dataset, you can use a builtin routine called cfg_hirni which is implemented as a Datalad
procedure. Ideally you create your dataset right at the moment you start (planning) your study. Even without any actual
data, there is basic metadata you might already be able to capture by (partially) filling dataset_description.json,
README, CHANGELOG etc. Hirni’s webUI might be of help here.
The idea is then to add all data to the dataset as it comes into existence. That is, for each acquisition, import the
DICOMs, import all additional data, possibly edit the specification. It’s like writing documentation for your code: If
you don’t do it at the beginning, chances are you’ll never properly do it at all.
You can always edit and add things later, of course.
Import DICOM files¶
Importing the DICOMS consists of several steps. The hirni-import-dcm command will help you, given you can provide it
a tarball containing all DICOMs of an acquisition (internal structure of the tarball doesn’t matter). Of course you can
achieve the same result differently.
The first step is to retrieve the tarball, of course, extract its content and create a dataset from it. If you passed an
acquisition directory to the command it will create this dataset in dicoms/ underneath that directory. Otherwise it
is created at a temporary location.
Then the DICOM metadata is extracted. If the acquisition directory wasn’t given, a name for the acquisition is derived
from that metadata (how exactly this is done is configurable) the respective directory created and the dataset is moved
into it from its temporary location.
Either way there’s a new subdataset beneath the respective acquisition directory by now and it provides extracted DICOM
metadata. Note, that the metadata doesn’t technically describe DICOM files, but rather image series that are found in
those files. The final step is now to use that metadata to derive a specification. This is done by hirni-dicom2spec,
which automatically is called by hirni-import-dcm. However, if you need to skip hirni-ìmport-dcm for whatever
reason (say you already have a DICOM dataset you want to use instead of creating a new one by such a tarball), you can
run hirni-dicom2spec. How the rule system is used to derive the specification deserves its own
chapter (at least if you wish to adjust those rules). This should now result in a
studyspec.json within the respective acquisition directory. You can now review the autogenerated entries and correct
or enhance them.
Add arbitrary data¶
Once an acquisition is established within a study dataset, you may add arbitrary additional files to that acquisition.
Protocols, stimulation log files, other data modalities … whatever else belongs to that acquisition. There are no
requirements on how to structure those additional files within the acquisition directory.
A specification for arbitrary data can be added as well, of course. It works the exact same way as for the DICOM data,
with the only exception that there’s no automated trial to derive a specification from the data. There is, however, the
command hirni-spec4anything to help with the creation of such a specification. It will fill the specification not
based on the data, but based on what is already specified (for the DICOMs, for example). So, hirni-spec4anything
will assume that specification values, that are unambiguous throughout the existing specification of an acquisition, are
valid for additional data as well. For example, if all existing specifications of an acquisition agree on a subject
identifier, this will be the guess for additional files.
This is how to create such a study dataset including its specification. See also this example.
Convert your dataset¶
The conversion of such datasets is meant to target a new dataset. That is, you create a new, empty dataset which is the
target of the conversion and make the study dataset a subdataset of that new one. Thereby the converted dataset keeps a
reference to the data is was created from. From within the target dataset you can then call hirni-spec2bids to
execute the actual conversion as specified in the specification files.
Note, that it is not required to convert the entire dataset at once. Instead, the conversion is called on particular
specification files and can be further limited to convert a particular type of data as listed in the respective
specification file.
Furthermore, hirni-spec2bids comes with an --anonymize switch. This will do several things: It will choose what
subject identifier to use in the converted dataset. For that a specification has a subject and a anon_subject field
to chose from. So, usually subject will contain the identifier as it comes from the DICOMs (likely pseudo-anonymized),
while anon_subject allows you to specify an anonymized identifier in addition.
Secondly, --anonymize will cause the conversion to encrypted generated commit messages in order to disguise possibly
revealing paths. Finally, conversion procedures listed in specifications can declare to be executed only if the
--anonymize switch was used. This mechanism allows to trigger things like a defacing after the conversion of DICOM
to Nifti.
An example of such a conversion is to be found here.